On the Magic Circle
Learning to pull apart applications and discover their secrets can sometimes feel like trying to work out how a stage magician performed a trick. In search of brevity, most authors show a polished, finished form, and ignore the thoughts that came in between the first cup of coffee and the result. You’ll hear things like “hacking is a mindset you can’t teach” often. It can’t possibly be true.
To be clear, I don’t think this is done on purpose, it’s more that we are in a world where we must be constantly running to keep pace, and slogging through wordy tutorials every week would get old. But, the 25th anniversary of the “exactly how to do it” masterpiece Smashing the Stack by Aleph One came up this week, as well as me seeing this beautiful process-focused post on reverse engineering. I happened to be working on something at the time that I think makes for a good walkthrough of how to solve a simple RE problem, so I got off my arse and wrote some words on a screen.
This post might be for you if: you have some programming knowledge, you have dabbled in reverse engineering enough to understand what a debugger does, etc. but haven’t jumped the confidence gap into getting work done with them yet. If you’re a crackme veteran, it’s not going to be interesting to you!
Making Assumptions
So, there I was, looking for vulnerabilities in… a piece of software. I’m not going to tell you which piece of software, but it’s written in PHP, and sold to businesses for money, so, they obviously have an interest in keeping their code secret. But, PHP being a scripting language that’s compiled at runtime, they are forced to distribute their source code to their customers.
Many such commercial apps use obfuscation solutions like Ioncube to protect their PHP from prying eyes, and this product appeared to do just that. If we look at one of their PHP files, all we see is this:
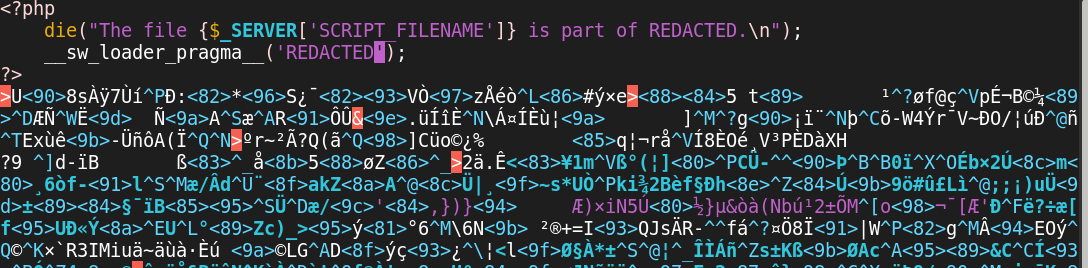
That’s clearly not PHP, and I knew from the prelude that it wasn’t Ioncube or similar, it looked to be a custom solution… not least because it mentioned the product by name until I redacted it. Whatever it is, it’s hindering our research efforts, so it’s got to go.
Before jumping into a reverse engineering exercise blindly, it is useful to make a cup of coffee and consider what assumptions we can make already based on what we know - and then how we could test them.
From the above, we can assume:
- The PHP interpreter will be invoked at some point, and run our code.
- The code is probably encrypted - it doesn’t look remotely like PHP code anymore, so it’s not just language level trickery that will run unaided, but mangled to look confusing to a human.
- Therefore, some sort of custom engine or extension is going to be used to decrypt it before it runs.
From experience with similar obfuscation engines, I know that a common way to achieve this is to skip using the parser and replace it with a custom loader that loads a compiled bytecode that the authors of the tool invent. This is similar to what tools like VMProtect do for native code and is a huge pain for RE, because it means we have to create a decompiler for a totally undocumented machine. It’s not impossible to do this - we have the runtime to study after all (the PHP engine has to know how to interpret the code!) but is a lot of work, and can be intentionally made harder with further tricks the author can do to frustrate our efforts.
But, we can make another assumption. Is the above likely? The authors of this software are interested in making their product, not in developing complicated, bug-prone obfuscation tools. If we are to assume this is a custom solution, then it’s more likely to use a simpler method that doesn’t create as much extra work.
So, first we will test another theory: that the code is decrypted to normal PHP source code when you run it, and then simply handed off to the standard PHP engine. Which means the original source is probably just hanging out in RAM somewhere waiting for us…
The Laziest Path to Validation
Of course, we don’t know if that’s actually true yet, it’s possible we stumbled across a developer with a lot of time on their hands who really likes writing novel bytecode interpreters (or really hates piracy!). So in order not to waste time, we should think of the quickest possible way we can check if our assumption is correct.
There’s a very quick way:
- Run the program, so it has to decrypt the code for us.
- Pause the execution of the program after it has started to run PHP code.
- Inspect its memory and see if it has our plaintext code in it now.
strace -s 50 -- /usr/bin/sw-engine /usr/local/psa/admin/htdocs/index.php
First, I ran the PHP script, via the custom PHP engine that the application uses, under strace. strace is a tool on Linux that can output every system call that a program makes while it’s running - other platforms will have similar diagnostic tools. My goal here is to find a system call that our script makes, that I can identify as definitely having originated within the code that we want to decrypt, and not from within the engine itself.
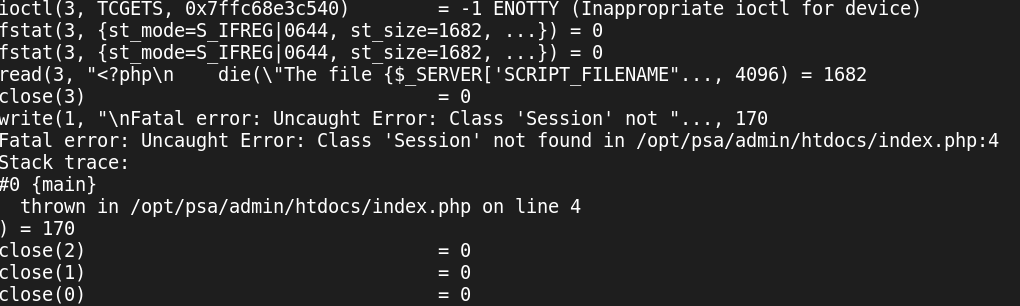
As you can see above, a read() system call is made to read our encrypted source
code from the file, and almost immediately afterwards a write() call is
made, to output an error message saying some class couldn’t be found. This error
message isn’t important - it’s just happening because we’re executing the
script
outside its usual environment, without the proper libraries loaded and so on.
But from the format of the error, we know we are executing PHP when the write()
is made - ‘Fatal error: Uncaught error’ is how PHP exceptions look when printed. And this is the
only write() call the application ever makes, so we can use this as a
breakpoint to stop the application. So, let’s switch to GDB.
Executing the following:
$ gdb /usr/bin/sw-engine
gdb> break write
gdb> r < /opt/psa/admin/htdocs/index.php
Will stop things where we want to be. But how do we find PHP code? Well, we can
assume it begins with <?php, as PHP code usually does. It’s possible they
have somehow set their engine up to not need that, but again - start with
assumptions. So, we search memory for <?php using
pwndbg’s search function. I highly
recommend, if you are using GDB, you install a suite of addons like pwndbg or
GEF, for your own sanity!

search lists all the locations in the memory space of our application where the
search term was found - the leftmost column is the segment of memory that it
was found in, colour coded by what kind of memory it is. The second column is
the address where the result was found, and the rest of the line shows the
result - with the value formatted differently based on the contents/location of the match.
We can immediately discount the first few results here. The first one at
0x8fbd70 might be confusing, since it is displayed here as assembly code, but it’s actually a valid result.
The ASCII bytes for the string <?php are 3c 3f 70 68 70, and if you plug
that into a disassembler you’ll see
that it does in fact disassemble to valid x86 - and that sequence of instructions happens to be in
our program! This actually happens a lot, particularly with x86. You could
probably drop a box of scrabble tiles on the ground and have the result be valid x86.
Don’t complain, it helps with
Return-Oriented Programming. :)
We can also ignore the next two, because pwndbg is showing us in the leftmost
column that they are found in the memory where the actual executable of our
program is located (our program in this case being the PHP runtime!). They
aren’t executable this time, so most likely they are string literals - you can
imagine that a parser’s code must have to contain the string ‘<?php’ somewhere.
(if($token == '<?php') ..)
The next result at 0x1710130 though is interesting - it’s in the heap. That is to say, memory
that the program allocated and wrote to while running… so maybe it’s our
code? We use x/s <address> to find out - this is GDB-speak for ‘print the
contents of the memory at that address as if it were a c string’.
But alas, this is our original, encrypted code that we already have. And that
makes sense, too - we knew it had been read in, from our earlier strace, and so it had to be
somewhere. One left, then, and this one is also in allocated memory -
the anon_ prefix here indicates memory requested with
mmap() - don’t worry if
that’s not familiar to you, it’s just important that it’s memory allocated at
runtime and not part of the executable.
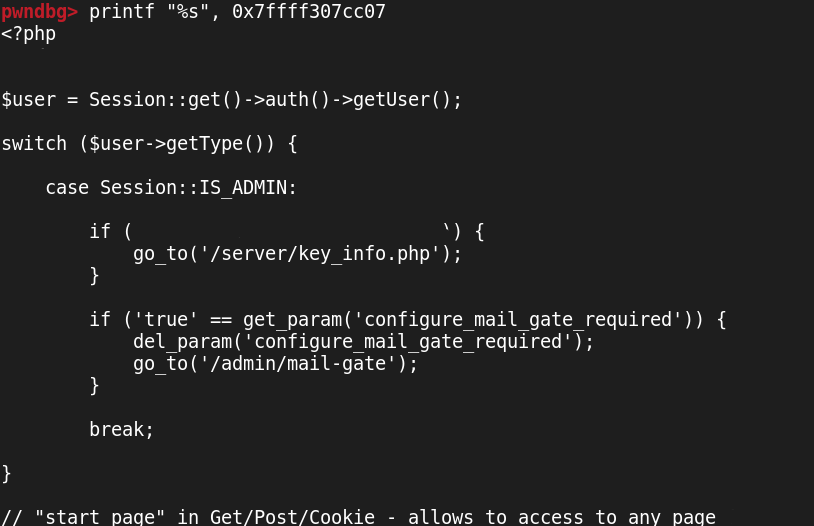
Success! As we suspected, the code is in memory for the taking. And, even better, the code itself isn’t obfuscated at the PHP level - variable names are present, and even comments haven’t been stripped, so we have a lot of information to go on for our further research.
Note: This time I used printf rather than x/s - this is just because it
handles new lines and makes for a prettier screenshot, rather than for any
technical reason. :)
Next Steps
So, we now know that our theory was correct, and we have a way to get source
code out now. But, this method is cumbersome, and not something we want to
repeat for thousands of files. It’s also not guaranteed to be reliable - what if
there are some scripts that don’t write() anything?
In the next post in this series, we will take a closer look at the decryption process, and build a tool to automate decryption using the Frida toolkit.
I would appreciate feedback on how I write these posts, by the way! I would like to do a lot more of this kind of thing for heftier topics, if I can wrap my head around how to write them well.